Using Key Columns with Writeback in Vizlib Collaboration
This topic contains the following sections:
Using Key Columns to Improve Speed and Accuracy
Applying Key columns in your Collaboration dataset can improve the speed and accuracy of your Writeback operations.
When you set Key columns for your Writeback operations, you're directing the matching and location of updates to your Collaboration dataset instead of triggering a general scan across your whole Writeback table.
This feature applies to your Writeback table's update, insert, and delete operations. Please see our article Vizlib Writeback Table Guides - Writeback Operations to learn more.
How Key Columns Work - Update Operation Example
After you make changes, the number of changes is shown by the Writeback button. Once you click the Update button to start your Writeback operation, it compares the current and previous values to match them to a row in the data source.
When it matches, the changes are saved and loaded back to Qlik Sense; however, not using Key columns with QVD files can result in lost changes if two users make updates to the same row and possibly performance issues as every value is checked against another.
While in SQL, this doesn't exist as a problem due to the nature of SQL and its primary keys, this is a problem for QVD.
When you use the update operation with a QVD destination without Key columns, it updates the entire row value, and you may see an error message that it can't find the change' of an overwritten change. It will show how many rows are modified, but this may not highlight where the lost change was.
Applying Key columns to act as a Primary key for QVD, where you can manually set a column as a key identifier, means that changes made to the row/value will always and only be applied to the values that match the identifier.
When to Use Key Columns
You don't need to use the Key Columns feature if you use the option to Match rows by Primary Key for a SQL destination in the Vizlib Management Console (VMC). The Key Columns feature offers the same benefits for QVD destinations that the option 'Match rows by Primary Key' has for SQL destinations.
Another scenario where you might use Key columns is if you have set a field as Primary Key in your SQL source data but may not have added that column to your Writeback destination.
You can use the Key Column feature for all Writeback destinations where you do not use primary keys with SQL, have not added that column to your Qlik data model, or any other destination type (e.g., QVD).
Selecting Key Columns
What makes a good Key Column?
A value that allows you to identify a single row - or as many as required to get a unique set for updates that affect a specific column. This precision search based on the combination of values set as Key columns ensures that all changes are saved- even when two users update columns that affect the same row.
Note: We highly recommend that Key columns be read-only and cannot be modified by end users. Similarly to a Primary key, the Key Identifiers must be unique. If the column is modified and columns aren't unique, the rows will be merged, and you can lose rows from your data.
Setting a Column as a Key Column
-
Click the heading of the column to view its properties.
-
Click Other Settings to view the section Key Constraint.
-
Click the box beside Key column to set the selected column as a Key column. Repeat the process to set the other (if any) columns required to create the group of unique fields for updates that affect a specific column.
Note: Key columns can't be excluded from Export Settings, as setting a column as 'Exclude from export' will remove the option to use it as a Key column.
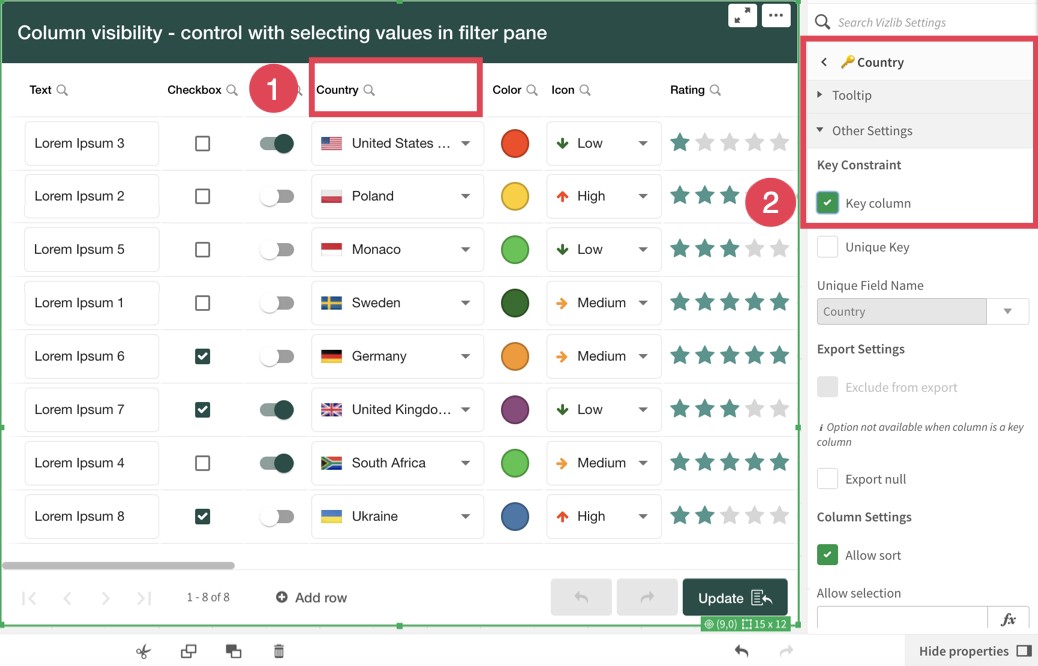
Figure 1: Setting a column as a Key Column.
All key columns display a key icon to the left of the column name so they are easily identifiable.
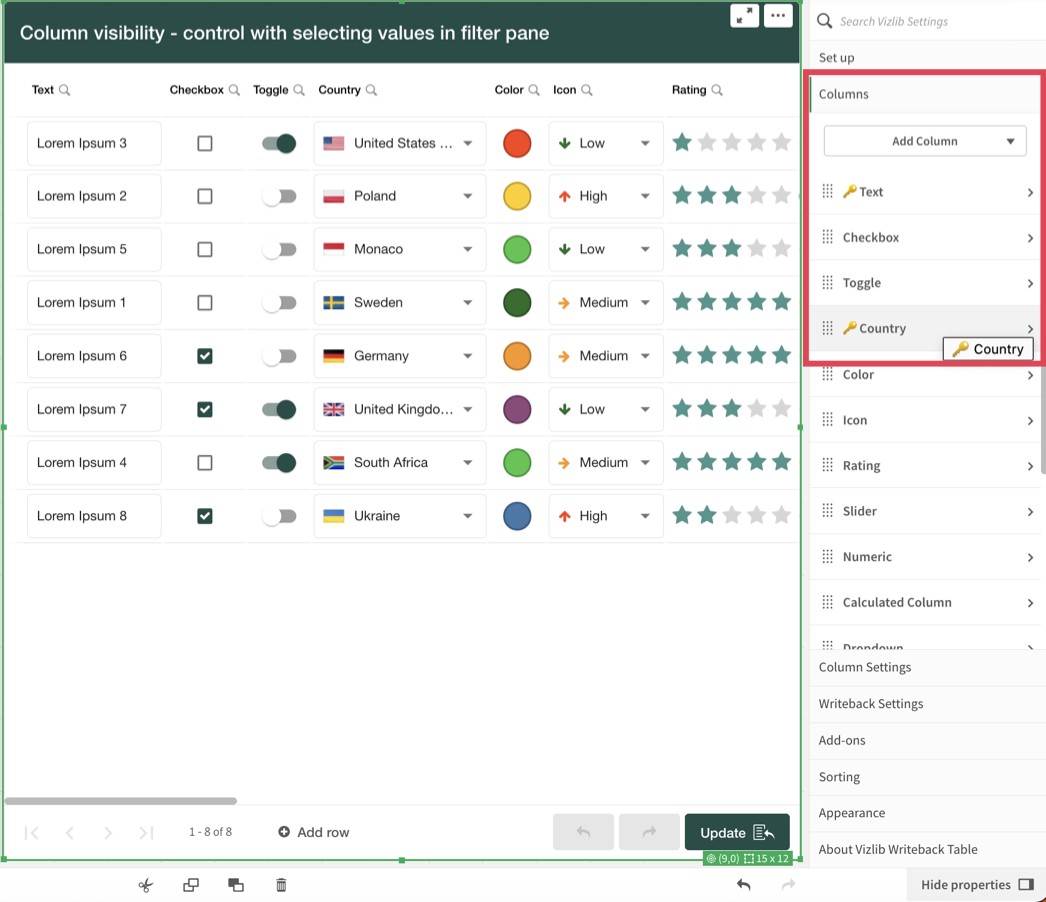
Figure 2: Viewing key columns in the properties panel.
Duplicate Key Error Message
The Duplicate Key error message: "Data Source contains rows with duplicate keys: There are X duplicated keys. For instance, the key value: X is not unique. Please apply selections to narrow down the data set or ask a developer to edit the key columns used in the table."
Added in version 4.10.0. the outcome of the Writeback operation now ensures that you are notified when there's an error in the setup of the data model you use with Writeback.
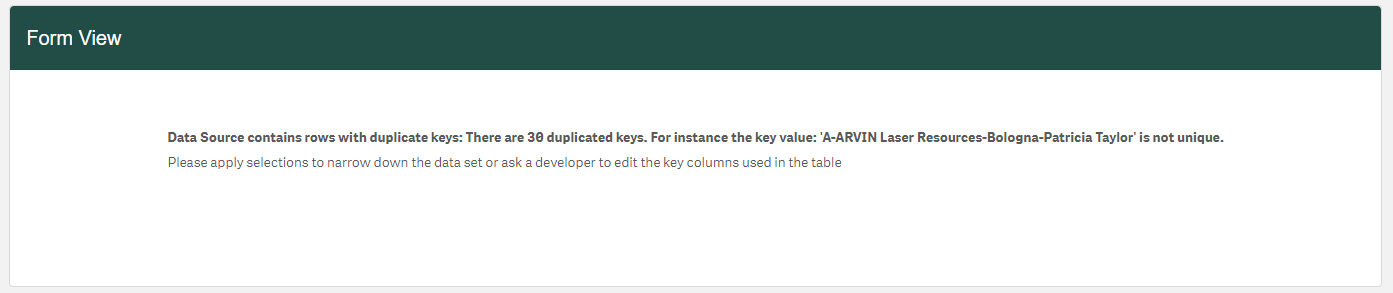
Figure 3: Duplicate key error message
This error displays when the Writeback operation prevents the table from being used when it detects rows loaded with the same key.
This check during the Writeback operation ensures the uniqueness of both inserted and updated rows; if there are duplicates, the error message displays with the number of duplicate keys and an example of the duplicated key values.
Setting a Unique Key
In the Key Constraint section, just below the Key column check box, is the Unique Key check box.
Selecting the Unique Key check box and the Unique Field Name prevents a Writeback operation when it detects that modified values would create duplicated keys in your data set.
Note: The Unique Key option works where only one column is set as a Key Column.
Using Key Columns with SQL Destinations
If you'd like to use Key Columns in an SQL destination, please use the following steps:
-
Log in to the VMC to check your settings.
-
Click Writeback Settings.
-
Click Destinations, and click your SQL destination.
-
The Edit Destination dialogue displays, scroll down to the section SQL Destination Settings (Figure 4).
-
Check the option selected in the Update/Delete options.
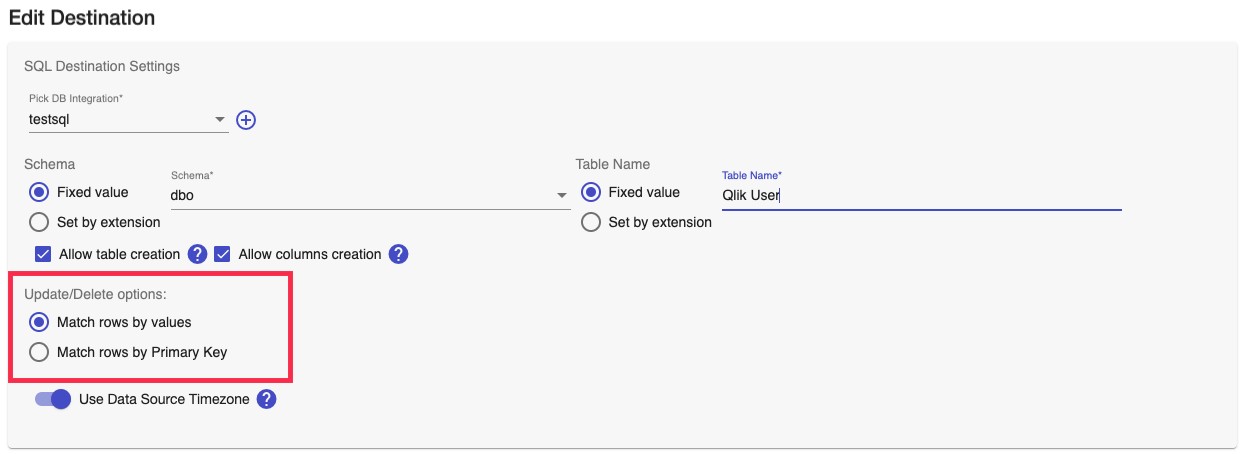
Figure 4: Edit SQL Destination in the VMC